ArchiveBox とは
いわゆる「魚拓」の OSS 版です。
スクリーンショット
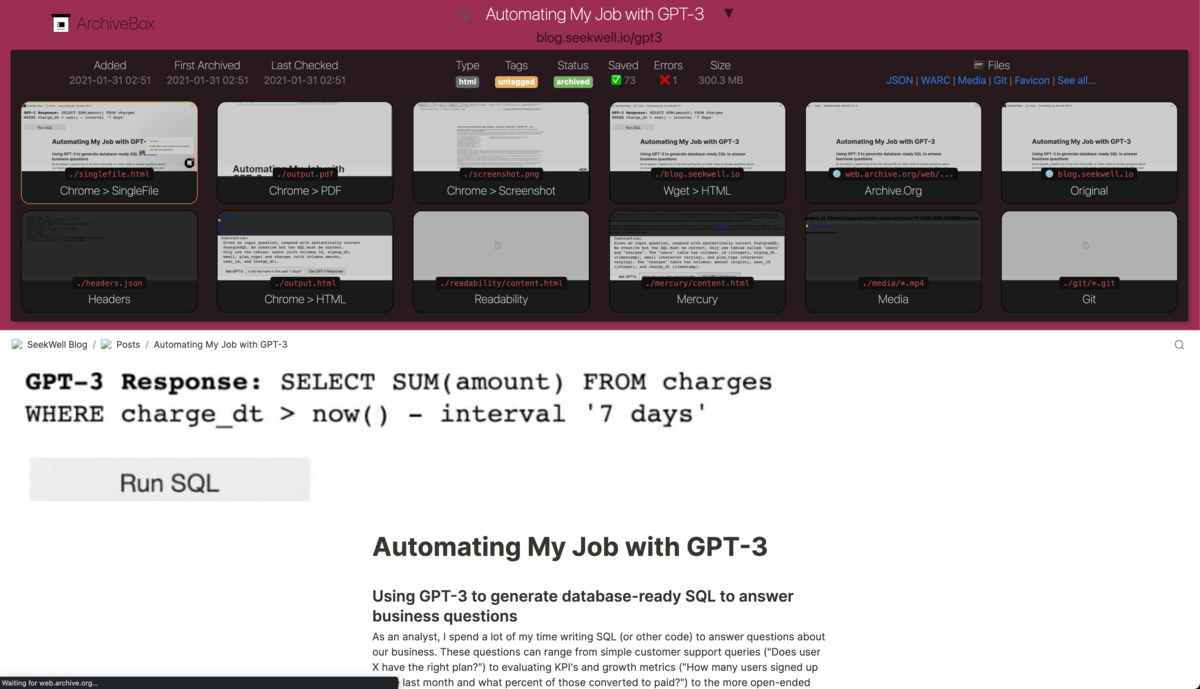
使い方
使い方は簡単です。公式で推奨されているように Docker Compose でほぼ事足りると思います*1。
設定
設定はデータボリュームのディレクトリ内の ArchiveBox.conf に書きます。WGET_USER_AGENT と TIMEOUT を適切に設定しないとダウンロードに失敗することが多かったので、そのあたりの設定をいい感じにいじります*2。
使いどころ
ここからが本題です。
いわゆる「魚拓」がしたいならばそれこそ特化したウェブサービスを用いるほうが簡単です。たとえば archive.today や Raindrop などです。僕は Raindrop に課金して使用しています。
となると、ArchiveBox の使いどころは「手元で気軽に取得データを再利用できる」ことにあると思います*3。
使ってみると分かりますが、ArchiveBox は Webアプリ として操作することが主体ではなく、コマンドで取得することが主体となっているように感じます。すなわちこれは、コマンドをパイプしたり cron で定期取得したりシェルスクリプトなどで一連の動作に組み込んだりといった目的で用いることを念頭に置いていそうです。そして現状の他 Webサービス の存在を考えると、それこそが ArchiveBox の使いどころであると感じています。
あとは気軽にスクショや PDF、warc が取得できることは魅力でしょう。さらに archive.org に登録してくれるということもなかなかに便利です。これらのことをコマンド一発でシュッとやってくれるということに ArchiveBox のアドバンテージを見ています。
さらに、既存サービスだと取得に失敗したり文字コードが期待どおりでなかったりする場合の補助的な用途にも便利です。
補足
このような OSS やツールで気になったものは、まずとにかく Docker で入れて使ってみるのが良いと思います。使っているといろいろと分かってくることもありますし*4、データの永続化や設定を煮詰めた上で改めて初期構築する、ということもできるからです。
机上で設定をしていざ本格運用、というのは現実のプロダクト同様に手戻りのリスクが高いでしょう。